
Overview
Welcome to The 3rd Competition on Human Identification at a Distance!
The competition focuses on human identification at a distance (HID) in videos. The dataset proposed for the competition is CASIA-E. It contains 1008 subjects and hundreds of videos sequences for each subject, and is a challenging dataset for HID. The winners will report their methods during IJCB 2022.
The organizers are all experienced researchers, have organized many related workshops, competitions, tutorials and seminars in the past 2 years.
How to join this competition?
The competition is open to anyone who is concerned about biometric technology.And it will be hosted in CodaLab HID 2022, where you can submit results and get timely feedback.
Note: Please use your institutional email to register for the competition, otherwise the registration will not be approved.
If you have any questions please contact me yusq@sustech.edu.cn and CC majz2020@mail.sustech.edu.cn, Thank you.
For the convenience of notification, please scan the QR code to join the WeChat group.
Competition Sample Code
We recommend using the OpenGait . It can help you start training quickly, and the baseline can reach about 68.7% accuracy ,and use re-rank trick can reach about 80%. The HID 2022 code tutorials for OpenGait can be click here.

Dataset and Evaluation Protocol
Dataset
How to get the data set?
Various data set download options are provided below:
- Google Drive.
- Baidu Drive password: HID3
The specific production process is: use cameras of different heights and viewing angles to collect video segments of people walking, and then obtain human silhouette images through human body detection and human body segmentation algorithms, and finally normalize these images to a uniform size.
The dataset proposed for the competition will be CASIA-E. It was employed for the competition. CASIA-E is a novel gait dataset created by the Institute of Automation, Chinese Academy of Sciences and Watrix company. The dataset contains 1008 subjects. There are about 600 video sequences for each subject. Those videos were collected from 28 views, which range from 0 to 180 degrees. The data was collected in 3 scenes. The backgrounds and floors may be different. The walking conditions of each subject may be normal walking, walking in a coat or walking with a bag.
To reduce the burden of participants on data pre-processing, we provided human body silhouettes. The silhouettes were obtained from the original videos by a human body detection deep model and a segmentation deep model provided by Watrix company. All silhouette images were resized to a fixed size 128 × 128. We did not remove bad quality silhouettes manually. All silhouettes are from automatic detection and segmentation algorithms. As show in the figure the silhouettes are not in perfect quality. Some noises in real applications are involved. The noises make the competition more challenging. It also makes the competition is a good simulation to real applications.
The dataset was separated into the training set and the test set. For each subject, 10 sequences were randomly selected from the dataset for the competition. The first 500 subjects are in the training sets, and the rest 508 ones are in the test set. Surely the labels of all sequences in the training set are given. But only 1 sequence of each subject in the gallery set is given its label. The other 9 sequences are in the probe set and need to be predicted their labels. The data for the competition is also described in below Table. Since the 10 sequences of a subject was randomly selected, they should be in different views, different walking conditions and different clothing. Considering only 1 sequence is in the gallery set for each subject, to distinguish 508 subjects is a challenging task.
| Training Set Subject #1-#500 |
Test Set Subject #501-#1005 |
||
|---|---|---|---|
| Gallery | Probe | ||
| Num. of Seq. | 10 | 1 | 9 |
In this competition, you are asked to predict the subject ID of the human walking video. The training set is available in the train/ folder, with corresponding subject ID in train.csv. During the test, the performance measurement method is the gallery-probe mode, which is commonly used in face recognition. Therefore, the test set consists of two parts, gallery set and probe set, which can be found in test_gallery/ and test_probe/ respectively. In addition, the subjects in the training set and the test set are completely different.
Evaluation protocol
How to identify human in the test process?

Each subject in the test set has a video in the gallery set, which will be used as a template. And you are asked to predict the subject ID of the video in a probe set based on gallery data. The usual identification method is to calculate the L2 distance between the probe and the gallery. Of course, you can also use other methods to calculate the similarity between the two.
The evaluation should be user-friendly and convenient for participants. It should also be fare and safe to be hacked. We designed detailed rules as follows:
- To avoid the ID labels of the probe set to be found by numerous submissions,we will limit the number of submissions each day to 2. Only one CodaLab ID is allowed for a team.
- The accuracy will be evaluated automatically at CodaLab. The ranking will be updated in the scoreboard accordingly.
- There will be about 40 days in the first phase. But only 25% of the probe samples will be taken for the evaluation in the first phase.
- There will be only 10 days in the second phase. The remaining 75% of the probe sample are for the evaluation. The data is different from that in the first phase.
- The top six teams in the final scoreboard need to send their programs to the organizers. The programs are for being ran to reproduce their results. The reproduced results should be consistent with the results shown in the CodaLab scoreboard.
File descriptions
train.csv– the training set label contains the ID corresponding to the video in the training settrain/– contains the training data, its file organization is./train/subject_ID/video_ID/image_data.test_probe/– contains probe data, its file organization is./test_probe/video_ID/image_data.test_gallery/– contains gallery data, its file organization is./test_gallery/subject_ID/video_ID/image_dataSampleSubmission.zip– a sample submission. Note that thesubmission.csvmust be placed in a zip archive and have the same file name. It Contains two columns of data, videoID, and subjectID. Every video in ./test_probe will require a prediction of subject ID. Finally, the result will be filled in this file. Note that thesubjectIDis int format.
Ethics
Privacy and human ethics are our concerns for the competition. Technologies should improve human life and not violate human rights. The dataset for the competition is CASIA-E which was collected by the Institute of Automation, Chinese Academy of Sciences. It contains 1008 subjects and was not released to the public in the past. All subjects in the dataset, CASIA-E, signed agreements to acknowledge that the data could be used for research purposes only. When we release the data during the competition, we will also ask the participants to agree to use the data for research purposes only.
In order to avoid potential privacy issues, we will only provide the binary silhouettes of human bodies as shown in below Figure, not RGB frames, to participants. The human IDs are labelled as some digital numbers such as 1, 2, 3, … and not their real identification information. Besides, we will also not provide the gender, age, height and other similar information from subjects.
Performance metric
Rank 1 accuracy is for evaluating the methods from different teams. It is straightforward and easy to implement.
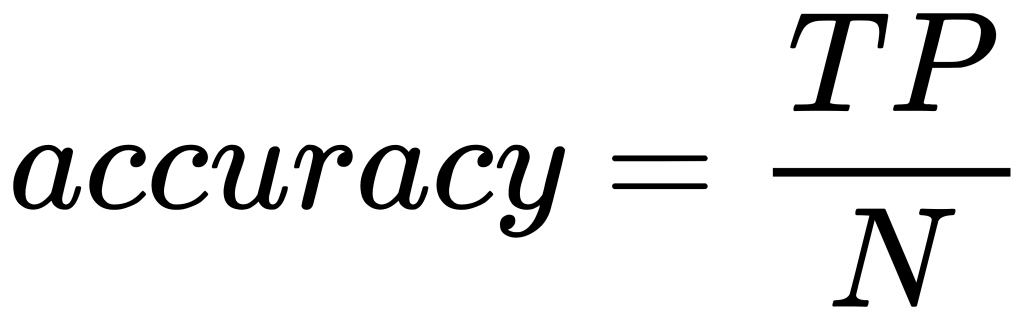
where, TP denotes the number of true positives, and N is for the number of
the probe samples.
Challenges and Solutions
Even we had a successful competition HID2020, we still should work hard to attract more participants. We hope to attain this goal by taking the following initiatives:
- To host the competition at codalab.org. codalab.org is a professional web site for competitions. codalab.org can evaluate the results submitted by participants automatically. That means the participants will get the recognition rates of their methods immediately after their submissions. Some codalab.org users will find the competition and participate it.
- To promote the competition through many different channels. Firstly, the organizers are all researchers in this field and are from different areas of the world. They will promote the competition in Europe, USA, China, Japan, Southeast Asia, and others. Secondly, We will also promote through email lists, Twitter, Facebook, WeChat and other social networking apps. Most of the committee members are active in the vision community with wider connections among related researchers.
- We will provide the preprocessed human body silhouettes. It will lighten the burden of data preprocessing for participants. This is aimed to ease any difficulties with approaching this material.
FAQ
Q: Can I use data outside of the training set to train my model?
A: Yes, you can. But you must describe what data you use and how to use it in the description of the method.
Q: How many members can my team have?
A: We do not limit the numbers in your team. But only one participant from each team can submit the result, otherwise, it will be considered an invalid result.
Q: Who cannot participate the competition?
A: The members in the organizers’ research group cannot participate the competition. The employees and interns at the sponsor company cannot participate the competition.
Q: Why are there empty folders in datasets?
A: Since the dataset generated randomly, it contains some empty files. You can refer the sample code to skip these folders.
Advisory Committee
Alphabetical order
- Prof. Mark Nixon, University of Southampton, UK
- Prof. Tieniu Tan, Institute of Automation, Chinese Academy of Sciences, China
- Prof. Yasushi Yagi, Osaka University, Japan
Organizing Committee
Alphabetical order
- Prof. Md. Atiqur Rahman Ahad, University of Dhaka, Bangladesh; Osaka University,
Japan - Prof. Yongzhen Huang, Beijing Normal University, China; Watrix technology co.
ltd, China - Prof. Yasushi Makihara, Osaka University, Japan
- Prof. Liang Wang, Institute of Automation, Chinese Academy of Sciences, China
- Prof. Shengjin Wang, Tsinghua University, China
- Prof. Shiqi Yu, Southern University of Science and Technology, China
Leaderboard
Acknowledgments
We would like to thank the Institute of Automation, Chinese Academy of Sciences for providing the dataset CASIA-E for the competition.